Instalación de Percona Cluster en RedHat 7 - Parte IV
Configuración del balanceador de carga y Uso.
Creación de base de datos y usuario para el portal en Drupal.
Ingresamos a uno de los nodos con el usuario root.

Y ejecutamos el siguiente grupo de sentencias SQL (Haciendo salvedad de cambiar el nombre de la base de datos por el que usted prefiera y usando una contraseña mucho más segura).

Balanceo de carga, script de chequeo
Al instalar Percona DB tenemos disponible un script llamado clustercheck ubicado en /usr/bin/clustercheck este script nos servirá para darle un estado a HAProxy sobre nuestro nodo.
De acuerdo a las instrucciones del script el cual puede ver al abrir el archivo /usr/bin/clustercheck debemos crear un usuario en la base de datos.
Ingrese a uno de los nodos como root y ejecute la siguiente sentencia SQL (Cambie la contraseña por una más segura).

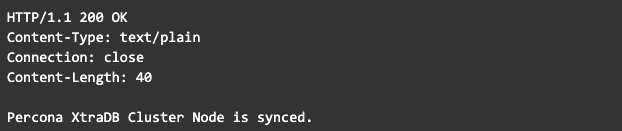
Para probar si todo está bien, podemos ejecutar el siguiente comando.

Si retornamos algo como lo siguiente, entonces estará bien.
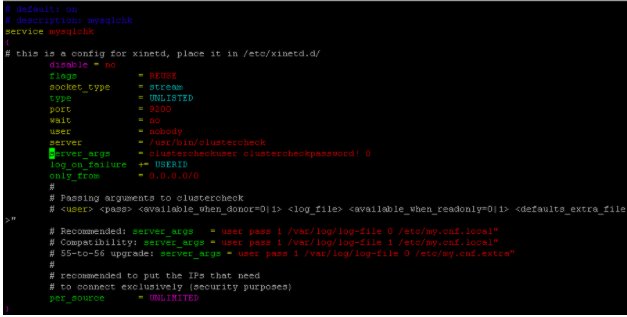
Vamos configurar el servicio en xinetd en cada uno de los nodos de base de datos editando el archivo.

Necesitamos pasarle como parámetros el usuario y contraseña en el comando, de la siguiente forma

Debe verse algo como lo siguiente
Ahora lo agregamos al listado de servicios

Vamos a reemplazar servicio ubicado en el puerto 9200 para que sea usado por el script, comentado el existente y agregamos el nuestro

Instalamos, Iniciamos el servicio xinetd y lo habilitamos para iniciar con el inicio de la máquina

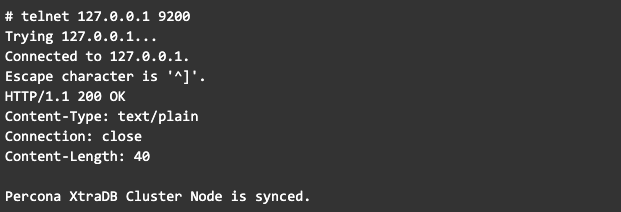
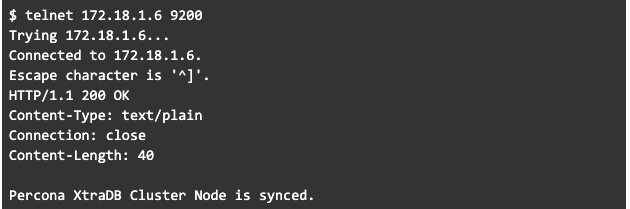
Para probar si todo está bien, puede hacer un llamado al puerto 9200 a la IP, localmente y desde el servidor que lo consultará
Instalación de HAProxy en servidor
Vamos a instalar HAProxy en el servidor que se ha destinado para este propósito.


Vamos a definir la configuración para los logs para haproxy.


Vamos a crear un nuevo archivo de configuración así que renombremos el que existe.

Ahora crearemos el nuevo archivo de configuración.

Agregamos este contenido al archivo (Tenga en cuenta que al final se define un usuario y contraseña que se ha establecido en portal:portal, le recomendamos cambiarla).
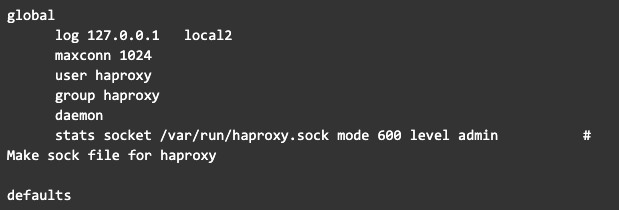
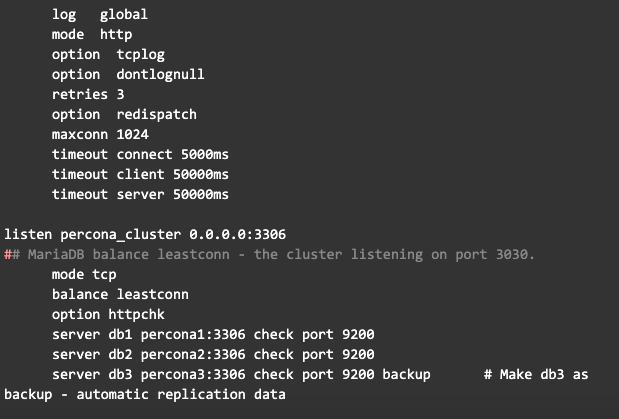
De la anterior configuración, podrá notar que hemos dejado el servidor db3 como backup, es decir que solo le llegarán peticiones si uno de los otros dos servidores no funciona, así reducimos cualquier problema de bloqueos por ser muchos servidores
También podrá notar lo siguiente
- El puerto de escucha para el balanceador de los nodos es el 3306
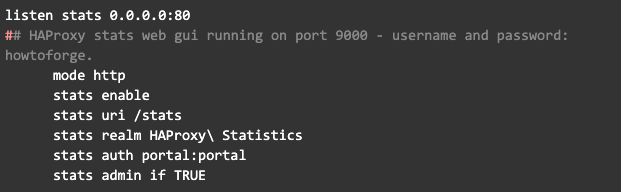
- El puerto de escucha para ver las estadísticas es el 80.
Iniciamos el servicio

Ahora podemos probar el servicio intentando la conexión directa al servidor balanceador por su dirección IP, si la conexión es buena entonces nuestra configuración ha sido exitosa.

Accediendo las estadísticas de HAProxy
Para acceder las estadísticas generadas por HAProxy, navegue la URL de servidor balanceador que en mi caso es http://172.18.1.8/stats al ingresar le pedirá un usuario y contraseña la cual fue configurada anteriormente, use esos datos
- Usuario: portal
- Contraseña: portal
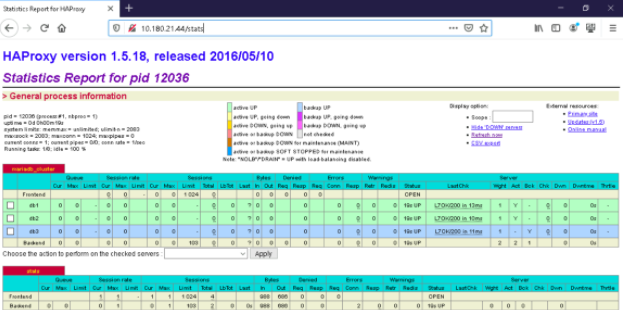
Al ingresar verá algo como lo siguiente (Note que esta versión de HAProxy está ya sin mantenimiento, considere usar una versión más reciente).
Uso en servidor Drupal
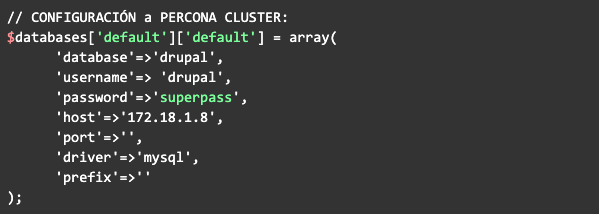
En la configuración de base de datos de Drupal puede configurarlo así:
Actividades comunes
Reinicio
Si se requiere reiniciar el servicio apagando todos los nodos, es importante que se asegure de apagar los nodos uno a uno y cuando los inicie los encienda desde el último apagado al primero.

Si falla el inicio es probable que no sea el último que se ha retirado, verifique el archivo /home/mysql-data/gvwstate.dat este contiene el último servidor visto, inicie arrancando ese servidor.
Notas finales
Espero que esta serie de artículos haya sido de ayuda para implementar su propio modelo de Cluster de base de datos y aunque puede que se pueda mejorar la implementación realizada, el objetivo es compartir el conocimiento que adquirimos en nuestro día a día.
Si desea leer la primera, segunda y tercera parte de este artículo le dejamos los links aquí:
https://www.seedem.co/es/blog/instalacion-de-percona-cluster-en-redhat-7-parte-i
https://www.seedem.co/es/blog/instalacion-de-percona-cluster-en-redhat-7-parte-ii
https://www.seedem.co/es/blog/instalacion-de-percona-cluster-en-redhat-7-parte-iii